- AI Productivity Insights
- Posts
- The Rise of Reasoning (Part 2)
The Rise of Reasoning (Part 2)
AI Model Reasoning Evaluation Framework — A Systematic Approach to Assessing Logic and Decision-Making in Artificial Intelligence Systems
Sumeth Manasikarn
February 23, 2025

Reading Time: 8 min ⏱️
Introduction
In Part 1 of The Rise of Reasoning, we looked at why reasoning is becoming more important in AI. As AI models evolve, they go beyond just recognizing patterns, which means they are not just finding repeated features in data but actually understanding and reasoning about new situations. Traditional AI models excel at identifying trends, like spotting faces in images, detect spam in emails or predicting stock market movements, but true reasoning requires deeper logical thinking.
Instead of just matching patterns, advanced AI models must evaluate information, draw conclusions, and make decisions based on context. In this part, I introduce the AI Model Reasoning Evaluation Framework, a structured way to test how well different AI models think and solve problems. This framework gives both numerical and descriptive insights into how AI models handle structured reasoning tasks.
AI Model Reasoning Evaluation Framework
To rigorously evaluate reasoning, I tested seven AI models using a standardized reasoning challenge:
Models Tested:
OpenAI o1
OpenAI o3-mini-high
Grok 3 (Beta)
DeepSeek R1
Gemini 2.0 Flash Thinking Experimental
Qwen2.5-72B
Mistral AI
Test Question:
A company has three teams working on AI development. Team A is twice as productive as Team B, and Team B is 1.5 times as productive as Team C. If Team C completes 20 tasks per week, and each task requires careful documentation:
How many total tasks do all teams complete per week?
If the company needs 200 tasks completed within a month, will they meet this goal?
What would you recommend to optimize the workflow?
This question was designed to assess multiple layers of reasoning, including computational accuracy, logical step breakdown, and workflow optimization.
Evaluation Criteria
To systematically score the models, I used a five-dimensional scoring system:
1. Computational Accuracy (25 points)
Correct calculation of Team B's output (20 * 1.5 = 30 tasks) [5 points]
Correct calculation of Team A's output (30 * 2 = 60 tasks) [5 points]
Accurate total weekly tasks (20 + 30 + 60 = 110 tasks) [5 points]
Correct monthly projection (110 * 4 = 440 tasks) [5 points]
Accurate goal assessment (440 > 200, meets goal) [5 points]
2. Reasoning Process (25 points)
Clear step-by-step problem breakdown [5 points]
Logical flow between steps [5 points]
Explicit statement of assumptions [5 points]
Handling of unstated variables (e.g., month length, consistent productivity) [5 points]
Error checking or validation steps [5 points]
3. Solution Quality (20 points)
Completeness of answer [5 points]
Precision in numerical expressions [5 points]
Clarity of explanations [5 points]
Proper handling of units (tasks/week, monthly projections) [5 points]
4. Optimization Recommendations (20 points)
Relevance to the scenario [5 points]
Practicality of suggestions [5 points]
Depth of analysis [5 points]
Consideration of constraints [5 points]
5. Response Structure (10 points)
Organization of information [2 points]
Formatting and readability [2 points]
Appropriate use of sections/paragraphs [2 points]
Conciseness vs. completeness balance [2 points]
Professional tone [2 points]
Model Performance Analysis
Each AI model was evaluated using the above framework, and their performance was analyzed based on the five key criteria. The results were visualized through comparative performance charts, including a radar chart comparing reasoning strength across different models.
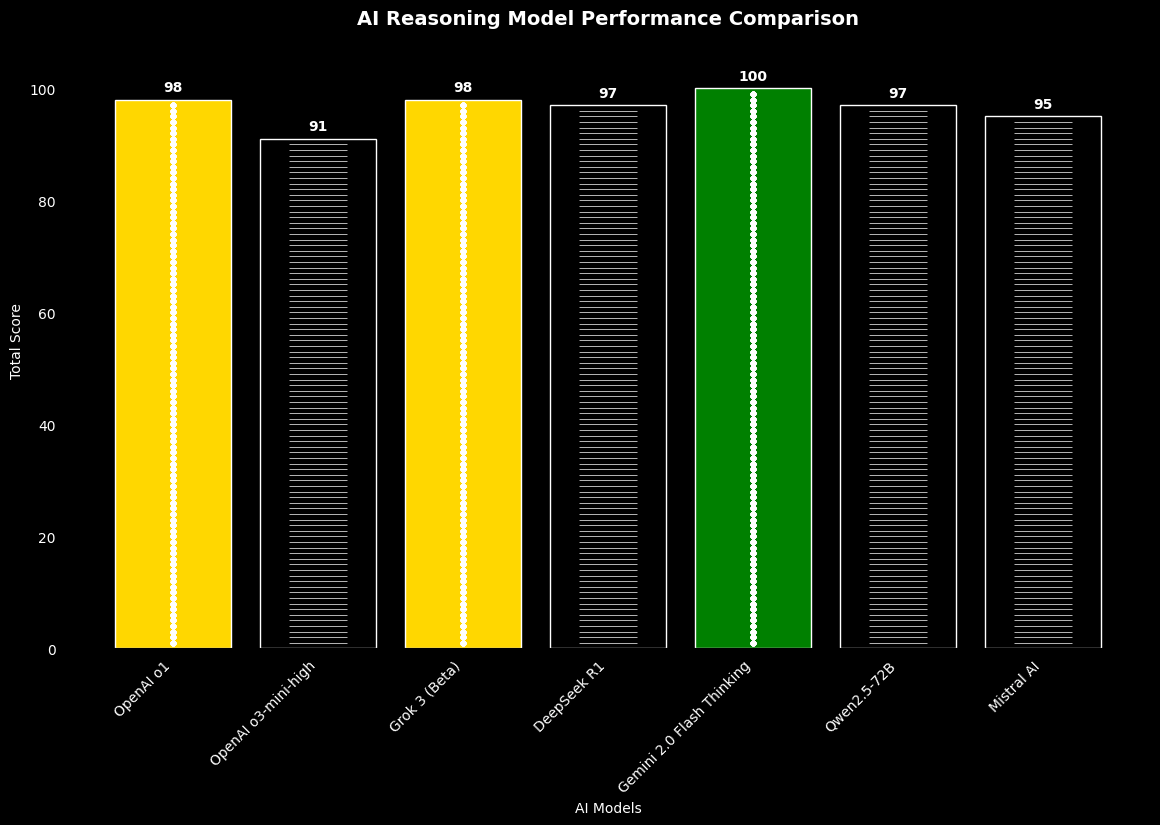
Figure 1: AI Reasoning Model Performance Comparison

Figure 2: A radar chart comparing reasoning strength across different models

Figure 3: AI Model Performance Comparison across Different Models
Key Analysis from the Visualizations
1. Total Score Distribution:
Gemini 2.0 leads with a perfect score (100/100)
OpenAI o1 and Grok 3 follow closely (98/100)
DeepSeek R1 and Qwen2.5-72B tied (97/100)
Mistral AI (95/100)
OpenAI o3-mini-high (91/100)
2. Category Performance:
Computational Accuracy: Almost all models perfect (25/25), except OpenAI o3-mini-high (23/25)
Reasoning: Clear leaders - Gemini 2.0 Flash and Grok 3 (25/25), followed by OpenAI o1 and Qwen2.5-72B (24/25)
Solution Quality: Three perfect scores (20/20) - Grok 3, Gemini 2.0 Flash, and Qwen2.5-72B; others close behind (19/20)
Optimization: Four models achieved perfect scores (20/20), with three models slightly behind (18-19/20)
Structure: Most models perfect (10/10), with Grok 3 notably lower (8/10)
3. Response Time Analysis:
Fast Tier (≤10s):
OpenAI o3-mini-high (5s, 91/100)
Mistral AI (5s, 95/100)
OpenAI o1 (10s, 98/100)
Medium Tier (11-25s):
Gemini 2.0 Flash (12s, 100/100)
Qwen2.5-72B (23s, 97/100)
Slow Tier (>25s):
Grok 3 (36s, 98/100)
DeepSeek R1 (68s, 97/100)
Key Insights:
Strong Overall Performance: All models demonstrated high competency, with scores ranging from 91-100
Computational Consistency: Nearly uniform excellence in computational accuracy
Differentiating Factors: Reasoning and optimization capabilities showed the most variation
Speed vs. Quality: Faster response times don't necessarily correlate with higher scores
Structure Importance: Most models maintained good structure, suggesting strong formatting capabilities
This analysis shows that while there are differences in performance, all models demonstrated strong capabilities in handling the AI development team productivity problem, with particular excellence in computational accuracy and varying strengths in other areas.
Key Findings Analysis
1. Performance Tiers
Top Tier (98-100): Gemini 2.0 Flash (100), OpenAI o1 (98), Grok 3 (98)
High Tier (95-97): DeepSeek R1 (97), Qwen2.5-72B (97), Mistral AI (95)
Base Tier (<95): OpenAI o3-mini-high (91)
2. Strength Analysis
Computational Excellence: All models except OpenAI o3-mini-high scored perfect 25/25
Reasoning Capabilities: Gemini 2.0 Flash and Grok 3 lead with 25/25
Optimization Skills: Most models showed strong capabilities (20/20)
Structural Quality: Consistent high scores except Grok 3 (8/10)
Enhanced Recommendations
1. Task-Based Selection
Time-Critical Tasks: OpenAI o3-mini-high or Mistral AI
Complex Reasoning: Gemini 2.0 Flash, OpenAI o1, or Grok 3
Balanced Performance: DeepSeek R1 or Qwen2.5-72B
Documentation/Structure:
Primary: Models with 10/10 structure (OpenAI o1, DeepSeek R1, Gemini 2.0 Flash, Qwen2.5-72B, Mistral AI)
Secondary: OpenAI o3-mini-high (9/10) and Grok 3 (8/10)
2. Implementation Strategy
Primary Choice: Gemini 2.0 Flash (100/100, 12s) - best overall performance
High Performance Backup: OpenAI o1 or Grok 3 (both 98/100) - different tradeoffs:
OpenAI o1: Faster (10s) with better structure
Grok 3: Slower (36s) with perfect reasoning
Fast Processing: Mistral AI or OpenAI o3-mini-high (5s) - speed vs. quality tradeoff:
Mistral AI: Better quality (95/100)
OpenAI o3-mini-high: Lower score but same speed (91/100)
3. Hybrid Approach
Speed + Quality: Pair OpenAI o1 (10s, 98/100) with Mistral AI (5s, 95/100)
Complex Tasks: Gemini 2.0 Flash (primary) with OpenAI o1 (backup)
Load Distribution: Balance between:
Fast tier models (≤10s): OpenAI o1, Mistral AI, OpenAI o3-mini-high
Quality tier models (≥97/100): Gemini 2.0 Flash, OpenAI o1, Grok 3, DeepSeek R1, Qwen2.5-72B
4. Monitoring Strategy
Track performance metrics:
Response times vs. score correlation
Consistency across different tasks
Quality-speed tradeoffs
Monitor real-world performance:
Accuracy rates in production
Response time stability
Resource utilization
5. Risk Mitigation
Primary-Backup Pairs:
High Performance: Gemini 2.0 Flash → OpenAI o1
Fast Response: Mistral AI → OpenAI o3-mini-high
Complex Tasks: Grok 3 → DeepSeek R1
Performance Monitoring:
Regular quality audits
Response time tracking
System load balancing
Contingency Planning:
Multiple model redundancy
Speed-quality fallback options
Resource scaling plans
Use Case Specificity
1. Real-time Applications (Priority: Speed with acceptable quality)
Primary:
Mistral AI (5s, 95/100) - Best speed-quality balance
OpenAI o3-mini-high (5s, 91/100) - Equal speed, lower quality
Backup: OpenAI o1 (10s, 98/100) - Slightly slower but higher quality
2. Complex Problem Solving (Priority: Reasoning and optimization)
Primary:
Gemini 2.0 Flash (100/100) - Perfect scores across all categories
Strong Alternatives:
Grok 3 (98/100) - Perfect reasoning but slower
OpenAI o1 (98/100) - Better response time
3. Balanced Performance (Priority: Consistent quality)
Primary:
Qwen2.5-72B (97/100) - Strong across all metrics
DeepSeek R1 (97/100) - Consistent performance
Backup:
OpenAI o1 (98/100) - Better speed-quality balance than Mistral AI
4. Documentation & Structure Tasks (Priority: Structure and clarity)
Primary:
Gemini 2.0 Flash (10/10 structure) - Perfect structure with best overall performance
OpenAI o1 (10/10 structure) - Excellent structure with fast response
Strong Alternatives:
All other models (8-10/10 structure) - Including Grok 3, as 8/10 is still competent
Essential Insights
While each model has strengths for specific use cases, the choice should consider:
Task priority (speed vs. quality)
Performance requirements
Response time constraints
Need for backup options
Major Findings and Observations
Computational Accuracy Trends: Some models consistently miscalculated intermediate steps, affecting their overall accuracy scores.
Reasoning Process Variability: Models differed significantly in their ability to clearly articulate assumptions and validate calculations.
Optimization Recommendations: More advanced models provided nuanced workflow optimization suggestions, while others struggled with practical recommendations.
Response Structuring: Higher-scoring models maintained clarity and logical flow, enhancing readability.
Conclusion
The AI Model Reasoning Evaluation Framework provides a structured methodology for assessing AI decision-making capabilities. By standardizing the evaluation process, I can objectively compare models and track their reasoning improvements over time. As AI systems continue to evolve, frameworks like these will be crucial in determining their real-world applicability and effectiveness.
Stay ahead of the curve in AI productivity by subscribing to AI Productivity Insights. If you found this guide valuable, consider sharing it with colleagues who are just as passionate about the evolving AI landscape. Together, we can explore the innovations shaping the future of AI-driven productivity. 🚀